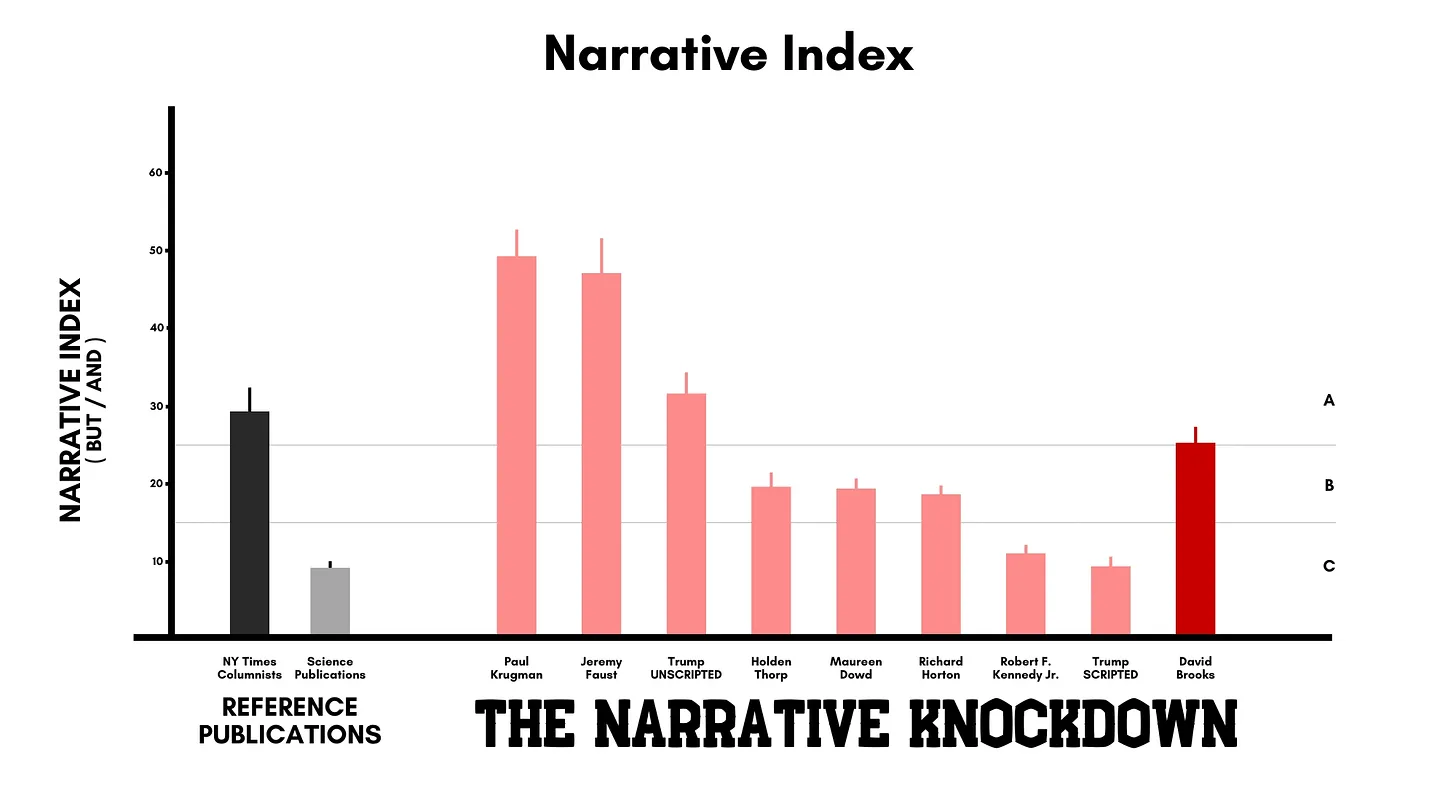
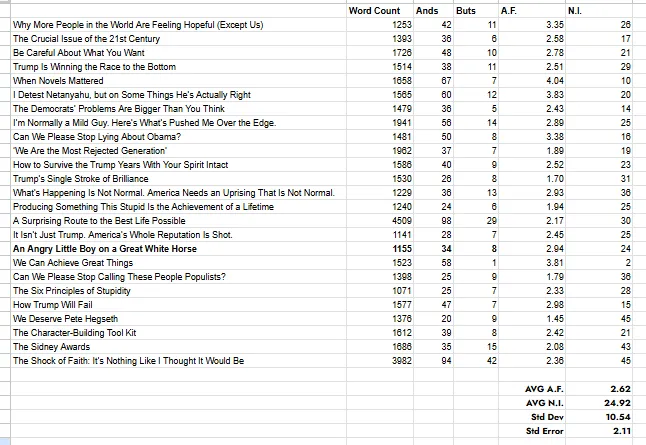
What are the optimum scores for the 2 narrative metrics? For the AND Frequency it’s 2.5%. But for the Narrative Index? Good question. David Brooks looks pretty optimal for both scores.

THE OPTIMA: Everyone knows 2.5% is the optimum for the AF (AND Frequency). Could it be that 25 is the optimum for the NI (Narrative Index)?
2.5% and 25?
I’ve known for a long time that the AF (AND Frequency) has an optimal value of 2.5%. I learned it in the Stanford Literary Lab’s study of the annual reports of the World Bank. They, in turn, cited the Longman Grammar study of 1999.
But what about the NI (Narrative Index)?
We (Narrative Metrics Team members Matthew David, Liz Strauss, and I) have been studying the writings and speeches of a series of individuals over the past couple months. We’re increasingly thinking there might also be an optimal value for the NI.
“Goldilocks-ing”: Too much narrative content, too little, and juuuuust right
We’ve speculated on the possibility that when the NI score gets above 30 there might be a risk of entering into the realm of “overly-narrative.” This means the DHY form (Despite, However, Yet). Our friend Andy Reynolds of NCQA addressed this specifically in our ABT mini-symposium in June.
At first we thought the sky high scores of Jeremy Faust, MD and economist Paul Krugman were the mark of communication brilliance, but lately … we’ve been wondering if there might be such a thing as “TOO MANY BUTS.”
David Brooks looks like an optimal communicator
I’ve always been a fan of David Brooks in the NY Times. His arguments seem clear, compelling, well thought out and well structured. He’s our focus this week and sure enough, he scores a near-perfect AF of 2.6%.
He also scores a very respectable 25 for the NI. In fact, we’re thinking that might be the ideal score. Enough BUTs to keep the energy going, but not so many as to be “shouting” or providing too many narrative directions.
And thus, this becomes our current thinking. That each of the two metrics has its own optimum.
Just a thought for now.